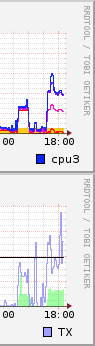
You've noticed a limit in throughput that's not a result of carrier or tc limits and have traced it to a correlation of ksoftirqd/0 (or ksoftirqd/x) maxing out 1 core.
You don't want the limit - it's just bloody annoying.
Most likley you have a very long list of IPtables rules, possibly a setup where a FireHOL-type block list is implemented to protect an external serivce... whatever it is, a LOT of IPtables rules need to be processed, possibly 20k rules or more per packet.
This has the effect that many software intterupts are generated, and processing these becomes the limiting factor.
There are 2 sides to this. Ideally, match the traffic with a rule close to the top of the list and permit early. This is the best option and gets you closer to wirespeed quicker. It is also possible that on a multicore CPU the load isn't being spread.
Here you can see that all the interrupts from ethernet adapters is being serviced by CPU0
# watch "cat /proc/interrupts"
CPU0 CPU1 CPU2 CPU3
...
103: 1860226124 0 0 0 PCI-MSI-edge eth0
104: 23413293 0 0 0 PCI-MSI-edge ahci
105: 37952817 0 0 0 PCI-MSI-edge eth1
106: 1970527575 0 0 0 PCI-MSI-edge eth2
107: 2526459 0 0 0 PCI-MSI-edge eth3
...

Setting /proc/irq/xxx/smp_affinity to force these interrupts to other cores will help in the event that CPU0 is at 100%.
# echo 2 > /proc/irq/103/smp_affinity # CPU 1 # echo 4 > /proc/irq/105/smp_affinity # CPU 2 # echo 8 > /proc/irq/106/smp_affinity # CPU 3 # echo 4 > /proc/irq/107/smp_affinity # CPU 2
see: https://cs.uwaterloo.ca/~brecht/servers/apic/SMP-affinity.txt
My outcome is now like this:
# watch "cat /proc/interrupts"
CPU0 CPU1 CPU2 CPU3
...
103: 1860281043 689621 10572 55553 PCI-MSI-edge eth0
104: 23432665 0 0 0 PCI-MSI-edge ahci
105: 37958918 897 8239 30691 PCI-MSI-edge eth1
106: 1970617707 97760 1841851 107842 PCI-MSI-edge eth2
107: 2527501 63 475 655 PCI-MSI-edge eth3
...

Network throughput improves by around 50%, correlating nicely to additional CPU useage